Airflow is Not a Data Pipeline Tool
If your Airflow tasks are doing real computation, your system is already mis-designed.
The symptoms are consistent:
- Workers pinned at high CPU
- Retry storms under load
- DAGs that pass locally but fail in production
- Business logic buried inside orchestration
This isn’t a scaling issue. It’s a boundary violation.
Airflow Is a Control Plane
Airflow exists to:
- schedule work
- enforce dependencies
- manage retries
It does not exist to:
- process data
- hold state
When orchestration and compute share the same layer, they compete for resources. That competition is where systems degrade.
DAGs Should Describe Flow — Nothing Else
A DAG answers:
- What runs, and in what order?
Not:
- How does the data get processed?
Once you embed logic inside DAGs:
- orchestration becomes coupled to implementation
- pipelines become untestable
- changes become risky
Clean systems separate:
- DAG → control flow
- Compute → execution layer
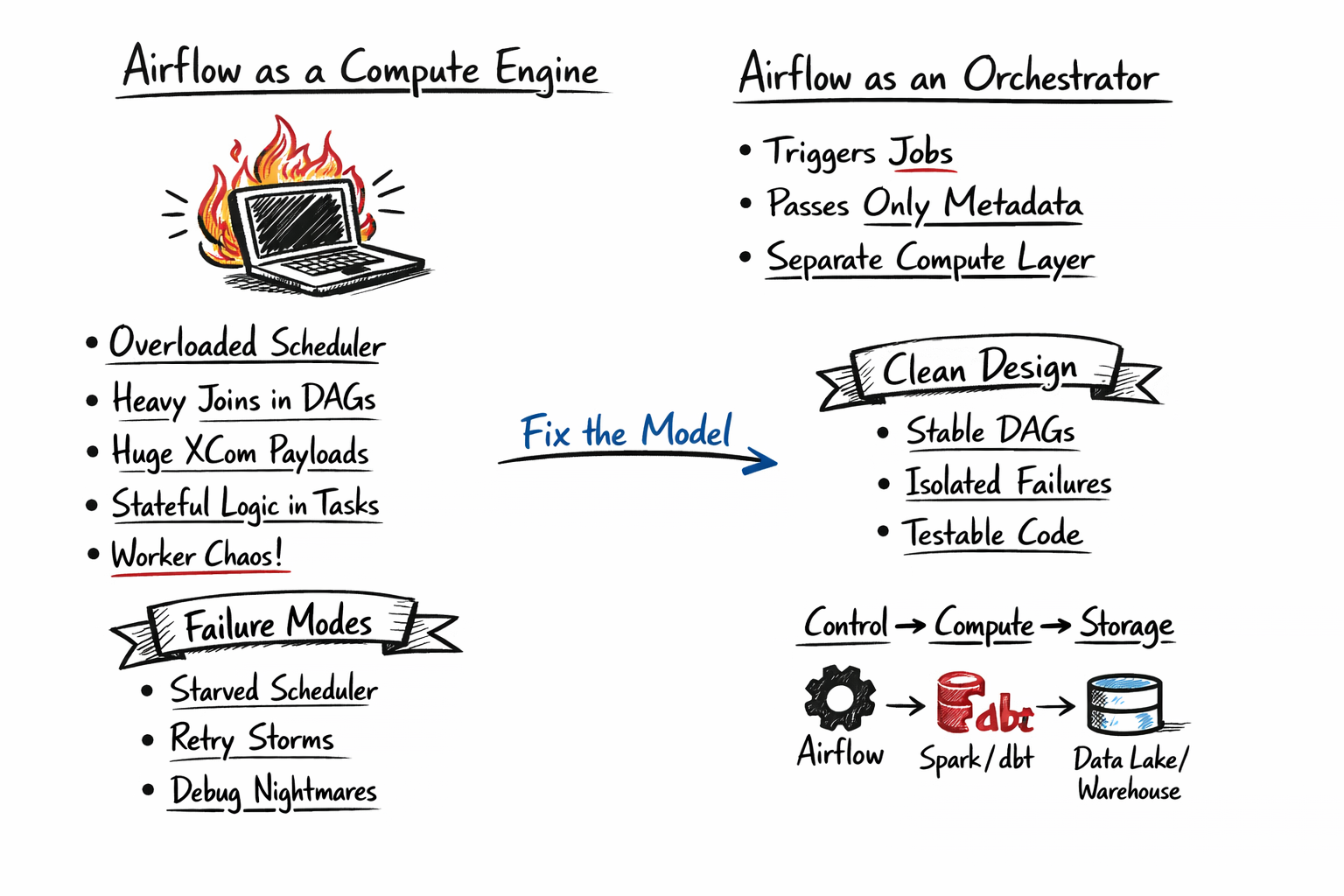
The Patterns That Cause Most Failures
- In-process compute: Large joins, pandas jobs, heavy transforms inside tasks
- XCom as a data layer: Passing payloads instead of metadata
- Business logic in DAGs: No versioning, no reuse, no testability
- Shared resources: Orchestration and compute competing for CPU/memory
These are not edge cases. This is how most Airflow systems fail.
Failure Modes (They Compound Fast)
- Scheduler starvation: Workers doing compute can’t schedule new tasks
- Retry amplification: Failures increase load → more failures
- State inconsistencies: No clear ownership of data or transformations
- Debugging collapse: Logs tied to orchestration, not execution
Failures don’t originate in SQL. They emerge at system boundaries.
The Correct Model
Airflow should coordinate work, not perform it.
- Trigger Spark / dbt / containerized jobs
- Wait for completion
- Pass references (IDs, URIs), not data
Airflow becomes thin, predictable, and stable.
What Improves in Production
- Scheduler remains responsive under load
- Failures are isolated to compute systems
- Pipelines become testable outside Airflow
- Recovery becomes deterministic
Not because of better tooling. Because responsibilities are separated correctly.
The System Model
Think in layers:
- Control → Airflow
- Compute → Spark / dbt / containers
- Storage → warehouse / lake
If these blur, the system becomes fragile.
Final Take
Most Airflow issues are self-inflicted. Not because Airflow is limited, but because it’s forced to do work it was never designed for.
If your DAGs are executing real computation, you don’t have a pipeline problem. You have a system design problem.
One Rule
If a task:
- runs long CPU workloads
- or processes large in-memory data
It does not belong in Airflow.
If you’re building data platforms, exploring lakehouse architectures, or just curious about how modern data systems achieve reliability, connect with me on LinkedIn.