I Dug Into Delta Lake's Transaction Log - This Is How ACID Actually Works on S3
I used to treat object stores like what they are: cheap, durable, and completely unreliable for transactional work. Great for dumping data. Terrible for updates, deletes, or anything resembling correctness.
A few years ago, if someone told me they were doing MERGE, UPDATE, DELETE on S3, I’d assume one of two things:
- They built a fragile abstraction
- Or they didn’t understand failure modes yet
Then I started digging into Delta Lake. What I found wasn’t magic. It was a very deliberate systems design trade-off.
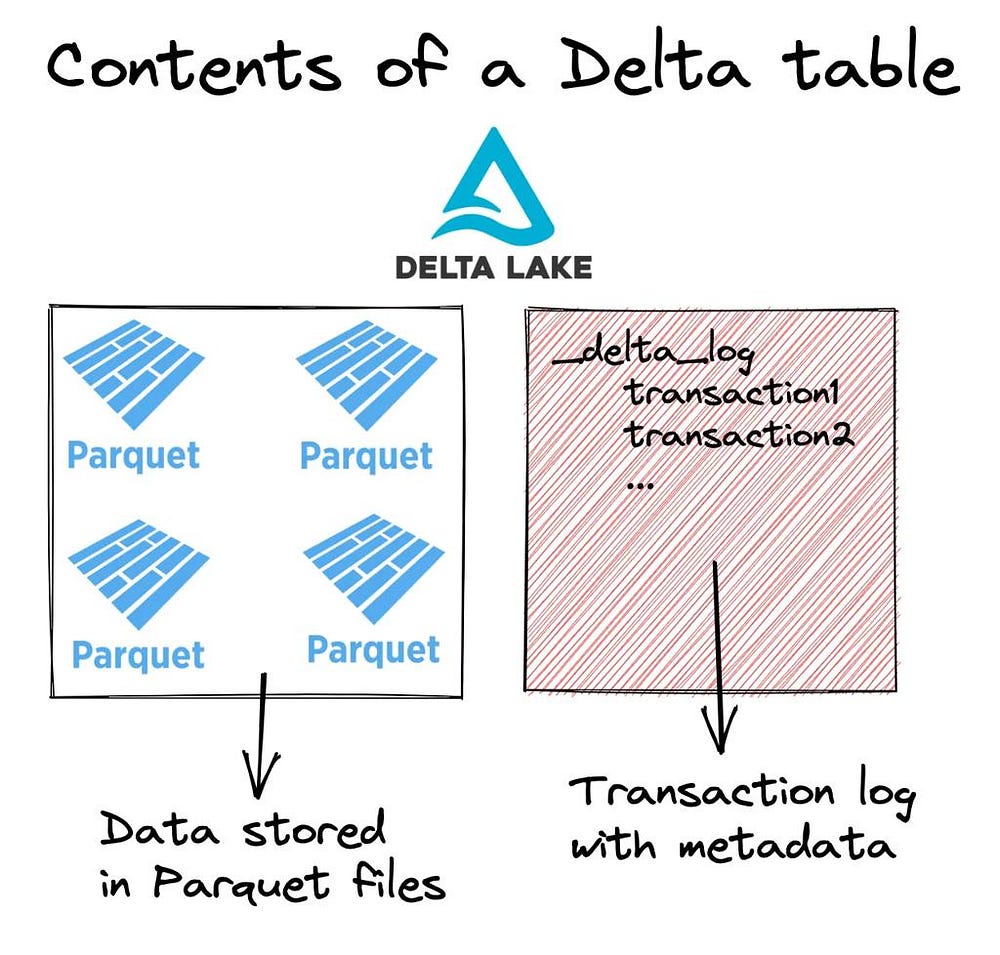 Delta Lake adds a transaction log layer on top of immutable data files
Delta Lake adds a transaction log layer on top of immutable data files
Why object stores break transactional systems
Object stores like S3, ADLS, and GCS were never designed for databases.
They give you:
- Immutable blobs
- High throughput reads/writes
- Cheap storage at scale
But they lack:
- Atomic updates
- Strong consistency on listing
- Transactions
- Native metadata layer
Which means: You can store data reliably - but you can’t change it reliably.
The core idea: don’t fix storage - add a layer
Delta Lake doesn’t try to make S3 transactional. Instead, it builds a thin transaction layer on top of it:
- Data files → immutable (Parquet)
- Changes → tracked separately
- Truth → defined by a log
This is the key shift: State is not in the files. It’s in the log.
Think of it like this:
- Files = raw facts (never edited)
- Log = source of truth
- Snapshot = interpretation of log + files
How Delta Lake actually gives you ACID
Three core building blocks:
1) Immutable data files
Data is written as Parquet Never updated in-place Updates = new files + mark old ones as removed
This avoids:
- Partial writes
- Corruption
- Complex locking
2) The transaction log (_delta_log)
Every change creates a new file:
_delta_log/
000000.json
000001.json
000002.json
Each commit contains:
- Files added
- Files removed
- Metadata changes
Periodically: Delta writes checkpoints (Parquet) So, you don’t replay everything from day one
3) Optimistic concurrency control
Instead of locks:
- Read latest snapshot
- Prepare changes
- Validate nothing changed
- Commit
If conflict: retry with new snapshot
The commit protocol (this is the real trick)
Object stores are unreliable for coordination. Delta works around it using:
- Atomic file creation → commit = new JSON file
- Validation before commit → detect conflicts
- Retries instead of locks → scale horizontally
No central coordinator. No database. Just files + discipline.
What ACID features you actually get
- Atomic commits → commit file exists or not
- Snapshot isolation → consistent reads
- Time travel → query past versions
- MERGE / UPDATE / DELETE → simulated via file rewrites
- CDC (Change Data Feed) → incremental pipelines
Minimal examples
Write
df.write.format("delta").mode("append").save("/mnt/lake/table")
Time travel
spark.read.format("delta").option("versionAsOf", 42).load("/mnt/lake/table")
MERGE (UPSERT)
from delta.tables import DeltaTable
tgt = DeltaTable.forPath(spark, "/mnt/lake/table")
(tgt.alias("t")
.merge(source.alias("s"), "t.id = s.id")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute())
Where things start breaking at scale
This is where most teams struggle:
1) Small file problem
Too many small files → slow queries
Fix:
- Compaction (OPTIMIZE)
- Target 100MB–1GB file sizes
2) _delta_log growth
Heavy writes → massive log
Fix:
- Frequent checkpoints
- Monitor log size
3) High write concurrency
Too many writers → retries explode
Fix:
- Partition-aware writes
- Queue + controlled writers
- Append + compact later
4) VACUUM risks
Deletes old files permanently
If misused:
- → breaks time travel
- → breaks downstream pipelines
Trade-offs
Pros
- Works on any object store
- No central DB required
- Enables Lakehouse architecture
- Scales extremely well
Cons
- Metadata overhead
- Operational complexity
- Retry-heavy under contention
- Requires discipline (not plug-and-play)
What I actually do in production
- Treat Delta as transaction layer, not storage
- Enforce file sizing + compaction
- Monitor _delta_log like a system metric
- Avoid high-concurrency small writes
- Be strict with schema evolution
The bigger picture
Databricks didn’t make S3 transactional. They accepted its limitations and built:
- a log-based abstraction
- with immutable data
- and optimistic commits
That’s it.
TL; DR
ACID isn’t coming from S3. It’s coming from _delta_log.
Files don’t define truth - the log does.
And once you understand that: You stop treating Delta like magic and start treating it like a system.
If you’re building data platforms, exploring lakehouse architectures, or just curious about how modern data systems achieve reliability, connect with me on LinkedIn.