
Most of us get comfortable because our code works, not because we fully understand why. And that illusion breaks the moment you hit edge cases that don’t behave the way you expect.
1. Default Mutable Arguments (but the real gotcha)
You already know this is bad:
def add_item(x, lst=[]):
lst.append(x)
return lst
But here’s what people miss: It’s not just a bug — it’s intentional state retention:
def counter(x, cache={}):
cache[x] = cache.get(x, 0) + 1
return cache
This acts like a hidden static variable.
💡 Used carefully → performance trick
💀 Used accidentally → nightmare debugging
2. is vs == (Worse Than You Think)
Everyone says: use ==, not is
But here’s the twist:
a = 256
b = 256
print(a is b) # True
a = 257
b = 257
print(a is b) # False
Python interns small integers (-5 to 256).
Even worse:
a = "hello"
b = "hello"
print(a is b) # True (sometimes)
💡 String interning is inconsistent across contexts.
3. Late Binding in Closures (Classic Trap)
funcs = []
for i in range(3):
funcs.append(lambda: i)
print([f() for f in funcs]) # [2, 2, 2]
👉 All lambdas capture same variable, not value.
Fix:
funcs.append(lambda i=i: i)
4. Dict Order Is Guaranteed (But That Changes Design)
Since Python 3.7:
d = {"a": 1, "b": 2}
👉 Order is preserved.
Hidden impact:
People now rely on dict order → implicit logic coupling
Old code assumptions break when ported.
💡 Dicts are now often used like lightweight ordered structures.
5. set Removes Duplicates… But Also Reorders
list(set([3, 1, 2, 1]))
# [1, 2, 3] (but not guaranteed order)
👉 Many devs accidentally introduce non-determinism.
6. Everything Is a Reference (But Not Always Obvious)
a = [1, 2]
b = a
b.append(3)
print(a) # [1, 2, 3]
But:
a = [1, 2]
b = a[:]
b.append(3)
print(a) # [1, 2]
👉 Copy vs reference bugs show up in:
- caching
- multiprocessing
- data pipelines
7. Tuple Isn’t Always Immutable
t = ([1, 2], 3)
t[0].append(99)
print(t) # ([1, 2, 99], 3)
👉 Tuple is immutable, but its contents might not be.
8. += Can Mutate… or Not
a = [1, 2]
b = a
a += [3]
print(b) # [1, 2, 3]
But:
a = (1, 2)
b = a
a += (3,)
print(b) # (1, 2)
👉 List mutates in-place
👉 Tuple creates new object.
Same operator. Different behavior.
9. Exception Handling Can Hide Bugs
try:
return something()
finally:
return "oops"
👉 finally overrides return.
10. for-else Exists (and Almost Nobody Uses It Right)
for x in data:
if x == target:
break
else:
print("Not found")
👉 else runs only if loop did NOT break.
11. Floating Point Lies
0.1 + 0.2 == 0.3 # False
👉 You know this… but it still bites in:
- finance
- aggregations
- data pipelines
12. List Multiplication Shares References
grid = [[0]*3]*3
grid[0][0] = 1
print(grid)
# [[1,0,0],[1,0,0],[1,0,0]]
👉 All rows point to same list.
13. bool Is a Subclass of int
True + True == 2 # True
isinstance(True, int) # True
👉 This leaks into:
- pandas
- aggregations
- weird bugs
14. __del__ Is Not Reliable
class A:
def __del__(self):
print("deleted")
👉 Garbage collection timing is unpredictable.
💀 Don’t rely on it for cleanup.
15. Iterators Get Exhausted Silently
it = iter([1,2,3])
list(it) # [1,2,3]
list(it) # []
👉 This causes subtle bugs in:
- streaming pipelines
- generators
- testing
16. Pattern Matching (3.10+) Has Sharp Edges
match x:
case 1:
...
case y:
...
But:
👉 This captures variable, not compares.
💀 Many devs think it’s equality.
17. Shadowing Built-ins Breaks Everything
list = [1,2,3]
list("abc") # 💀
👉 Happens more in notebooks than you think.
18. globals() and locals() Are Writable (Sometimes)
You can do wild stuff like:
globals()['x'] = 10
👉 Useful for metaprogramming
💀 Dangerous in large systems.
Final Take
Most Python bugs aren’t syntax issues.
They’re mental model mismatches.
Python looks simple — but it’s full of “gotchas by design.”
]]>
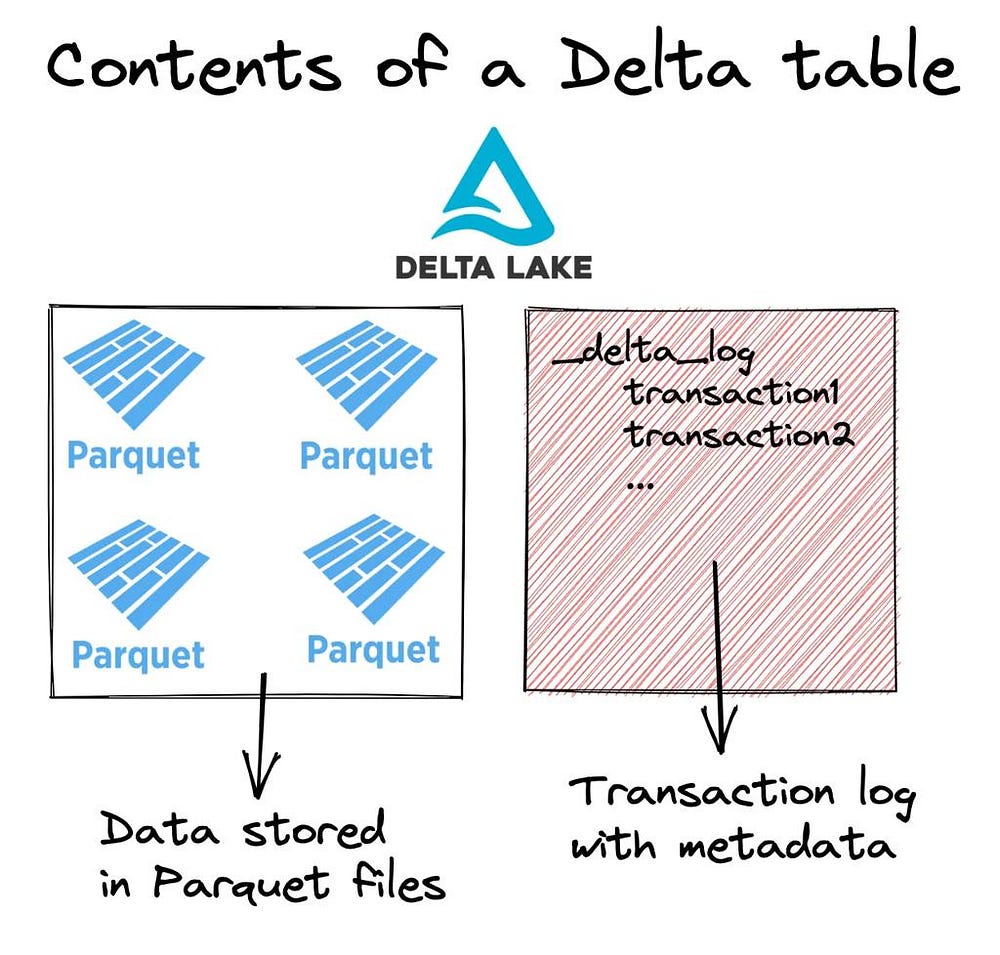 Delta Lake adds a transaction log layer on top of immutable data files
Delta Lake adds a transaction log layer on top of immutable data files